Tiếp nối bài viết trước, mình đã chia sẻ về ý tưởng ban đầu khi nhận ra mình “tụt mood” thế nào mỗi lần gặp hàng tá từ mới trong trải nghiệm đọc sách tiếng Anh. Lần này, chúng ta sẽ cùng nhau đi sâu hơn vào quy trình hiện thực hóa ý tưởng ấy thành một prototype có thể hoạt động được.
1. Phác thảo hành trình người dùng
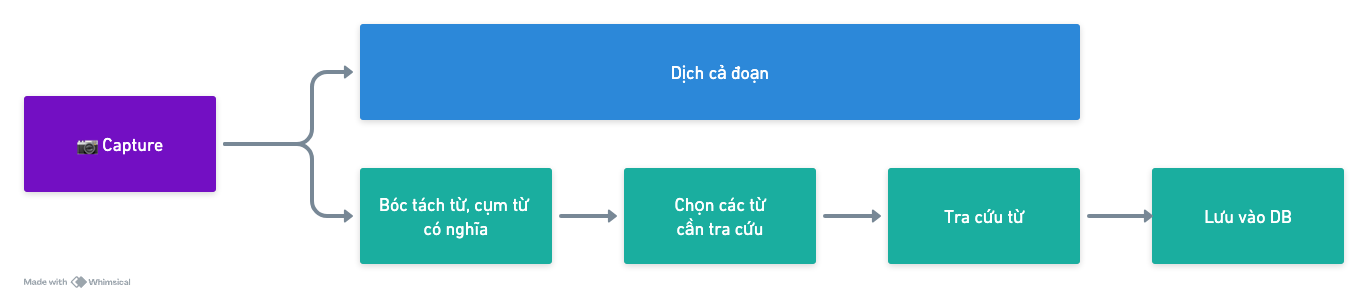
Như mình từng đề cập, mục tiêu cốt lõi của SnapVocab là giảm tối đa sự gián đoạn khi đọc sách tiếng anh trên Kindle. Vậy nên, mình hệ thống hóa ý tưởng theo một userflow 5 bước:
**1. Capture (Chụp)**Người dùng chụp màn hình trang sách hoặc đoạn văn đang đọc (trên Kindle, web, PDF, v.v.).
2. Xử lý văn bản – Lúc này người dùng sẽ có hai lựa chọn:
- Dịch cả đoạn: Hệ thống sẽ dịch toàn bộ đoạn văn bản.
- Bóc tách từ riêng lẻ: Tách từ vựng trọng tâm có nghĩa.
3. Chọn từ cần tra cứuNgười dùng chọn những từ mới cần tra.
4. Tra cứu từHệ thống sẽ trả về ý nghĩa của các từ vựng đã chọn.
5. Lưu vào cơ sở dữ liệuCác từ vựng và thông tin liên quan (ngữ cảnh, ví dụ) được lưu trữ để dùng về sau.
Chia quy trình thành hai phần lớn
Phần 1: Trích xuất văn bản từ hình ảnhMình đã xử lý phần này bằng Apple Shortcuts để tự động chuyển ảnh chụp thành dạng text. Phần này trước đây đã được mình thử nghiệm, nên tính khả thi cao và không cần tốn thêm thời gian “chứng minh” nữa.
Phần 2: Bóc tách & tra từĐây là linh hồn của SnapVocab. Sau khi có text, mình tiến hành phân tích, tách từ — rồi cuối cùng là tra cứu nghĩa và lưu lại thông tin.
2. Tư duy nền tảng khi tạo prototype với AI
Khá trùng hợp, đúng lúc này mình đang học khoá AI Prototyping của Sơn Võ, nơi Sơn chia sẻ cách tận dụng AI để build prototype hay thậm chí là MVP. Song song với việc xác định userflow, mình áp dụng những gì học được từ khóa học của Sơn, với các keyword then chốt:
PRD (Product Requirement Document) là trái timXây dựng 1 PRD tốt ngay từ đầu sẽ giúp mình định hướng và kiểm soát tốt quá trình build Prototype với AI.
Roadmap – kim chỉ namSau khi để AI “nạp” đủ thông tin, nó có thể bị “ngáo” nếu không được nhắc nhở liên tục. Việc có một roadmap cụ thể buộc AI phải bám sát mục tiêu ban đầu, tránh sinh ra những ý tưởng quá lan man.
ERD (Entity Relationship Diagram) – xương sống của backendViệc chốt ERD ngay từ đầu giúp hạn chế rủi ro phải refactor nặng về sau, đặc biệt là khi snapshot data của người dùng đã nhiều.
Chia để trịThay vì ôm đồm mọi thứ cùng lúc, hãy chọn cách chia toàn bộ dự án thành nhiều phiên bản (version), và trong mỗi phiên bản lại tiếp tục “chẻ” thành các bước (step) cụ thể. Điều này giúp kiểm soát tốt từng giai đoạn, hạn chế rủi ro khi thêm tính năng mới hoặc tăng độ phức tạp.
3. Bắt tay xây Prototype với Lovable
1. Xây dựng PRD
Mình bắt đầu bằng việc brainstorm với Claude, đưa cho nó userflow và ý tưởng ban đầu, kèm theo một template PRD mình mong muốn. Claude đã giúp mình chỉnh sửa và hoàn thiện PRD với các mục tiêu, tính năng, và userflow chi tiết.
Ghi chú: PRD không cần quá hoàn hảo, nhưng phải đủ rõ ràng để AI hiểu được mình muốn gì.
2. Thiết kế UI với Lovable
Sau khi có PRD, mình nhập nó vào Lovable và bùm! Bất ngờ với bản UI đầu tiên khá ổn áp. Lovable không chỉ tạo ra giao diện mà còn hiểu được flow của ứng dụng mình muốn xây dựng.
Một tip nhỏ: Sau khi có UI đầu tiên, mình đã nạp PRD vào phần Knowledge Base trên Lovable. Điều này giúp nó luôn nhớ và bám sát PRD, hạn chế việc “em đi xa quá em đi xa tôi quá”.
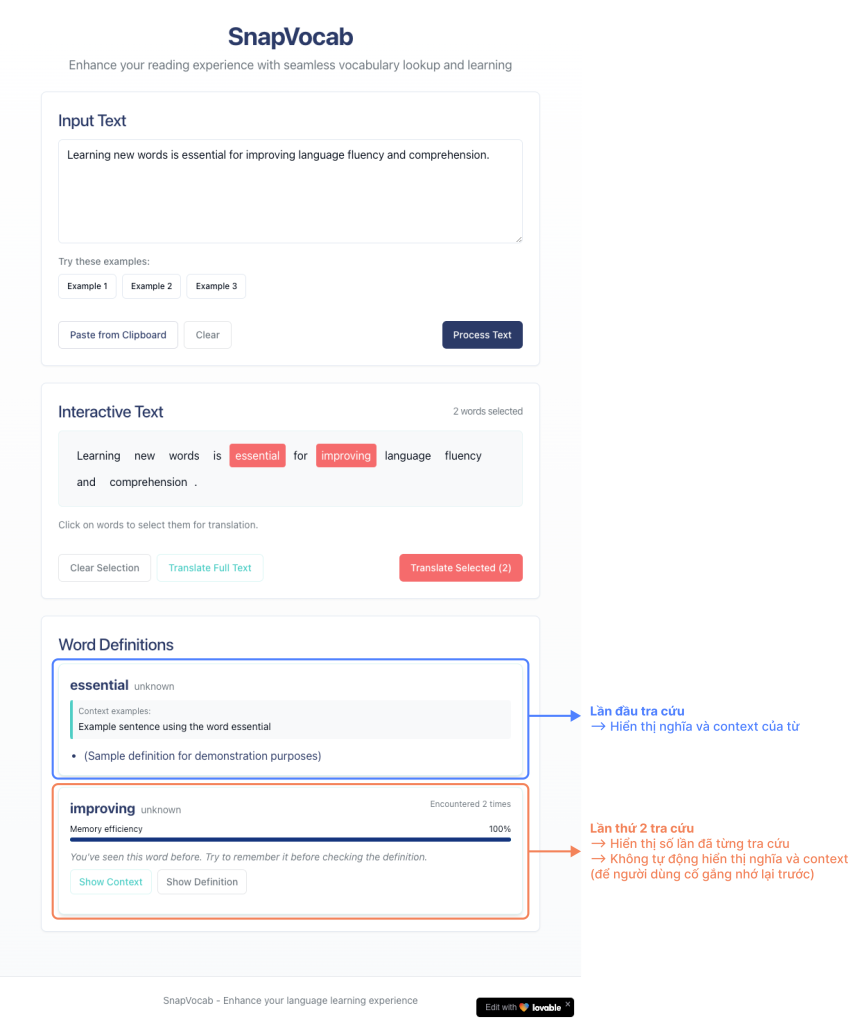
Version UI đầu tiên được tạo ra bởi Lovable.
3. Kiểm soát quá trình
Mình luôn bắt Lovable viết lại roadmap và liệt kê những thứ nó đã làm được sau mỗi phiên làm việc. Điều này giúp cả mình và AI không bị lạc khỏi mục tiêu ban đầu.
Sau vài lần prompt, mình đã có bản UI version 1 khá ưng ý. UI có đầy đủ các tính năng chính:
- 1 ô để nhập văn bản cần tra cứu
- Tính năng cho phép tách văn bản thành từng từ riêng biệt
- Người dùng có thể chọn các từ vựng cần tra cứu
- Hệ thống trả về nghĩa của từ, kèm các chỉ số đánh giá mức độ ghi nhớ của từ
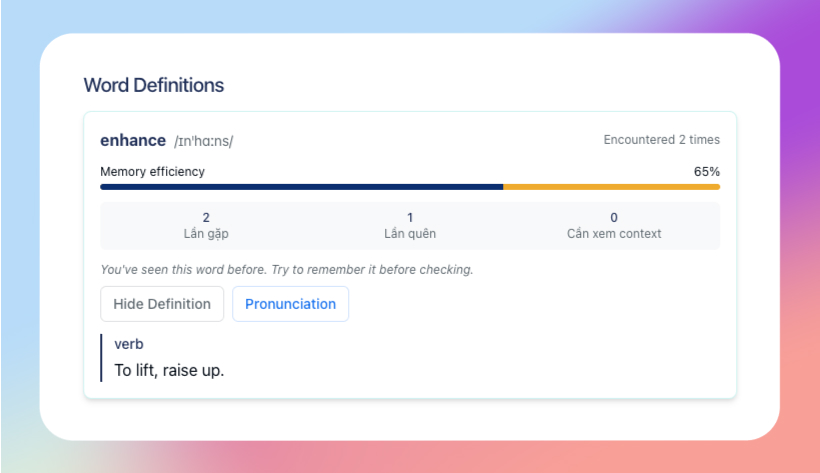
4. Thiết kế database với Supabase
Để có cơ sở dữ liệu, mình nhờ Claude đề xuất mô hình ERD phù hợp với PRD đã có. Claude đã đưa ra một thiết kế với các bảng chính:
- users: Thông tin người dùng
- words: Danh sách từ vựng
- user_words: Mối quan hệ giữa người dùng và từ vựng
Có hai cách để tạo database trên Supabase:
- Để Lovable tự tạo theo ERD được cung cấp
- Tự tạo trên Supabase
Vì giới hạn số lượt message trong 1 ngày của Lovable, mình quyết định nhờ Claude tạo sẵn câu lệnh SQL, rồi mình tự chạy trên Supabase. Sau đó chỉ việc kết nối Lovable với Supabase và bảo nó follow theo những thứ đã có sẵn. Chiến thuật này giúp tiết kiệm được kha khá lượt chat với Lovable!
5. Kết nối API từ điển
Sau khi đã có UI và database, mình cần một API từ điển để tra nghĩa. Lại một lần nữa, Claude giúp mình tìm API miễn phí phù hợp: https://api.dictionaryapi.dev
API này có nhiều ưu điểm:
- Miễn phí và không cần key
- Có file audio cho phát âm
- Cung cấp đầy đủ thông tin về loại từ, định nghĩa, ví dụ…
Ở bước này, mình yêu cầu Lovable thực hiện kết nối với API này, lấy nghĩa của từ và lưu vào database trên Supabase.
Kết quả và kế hoạch triển khai tiếp theo

Đây là demo những tính năng mình đã làm xong trong giai đoạn 1. Bước tiếp theo sẽ triển khai tính năng Đăng nhập/Đăng ký người dùng.
Để bạn dễ dàng theo dõi hành trình xây dựng SnapVocab từ đầu, mình sẽ luôn cập nhật các bài viết liên quan tại đây:
(Danh sách này sẽ được cập nhật liên tục mỗi khi có bài viết mới.)
Cùng đồng hành với mình nhé!
Mỗi ngày, khi SnapVocab có thêm một bước tiến mới, mình sẽ đều chia sẻ lại quá trình, những khó khăn gặp phải và cách mình giải quyết chúng.
Nếu bạn cũng đang gặp vấn đề tương tự khi đọc sách ngoại ngữ, hoặc đơn giản là tò mò về cách xây dựng một sản phẩm từ con số 0, hãy đồng hành cùng mình nhé!





 Tiếp nối bài viết trước, trong bài viết này mình sẽ chia sẻ chi tiết hơn về những suy nghĩ và trải nghiệm của mình với Lovable – công cụ mình dùng để build SnapVocab.
Tiếp nối bài viết trước, trong bài viết này mình sẽ chia sẻ chi tiết hơn về những suy nghĩ và trải nghiệm của mình với Lovable – công cụ mình dùng để build SnapVocab.